How Easy is It to Rush Lambdas
Making Sense of Big Data
AWS Lambda - 7 things I wished someone told me
A short guide to fast track your journey on AWS Lambda and save money and time

AWS Lambda is quite simple to use but as the same time it can be tricky to implement and optimize. In this post I summarized 3 years of experience working with this service. The result is a list of 7 things I wish I already knew when I started, from service logic, DB connections management and cost optimization. Hope this helps people starting off.
AWS Lambda is Amazon "Function as a Service" (FaaS), a category of cloud computing services that allows customers to run application functionalities without the complexity of maintaining the infrastructure. You pay only for the compute time you consume, which is great, and there is no charge when your code is not running.
1- How it works — Containers creation and recycling

First things first, how does AWS Lambda work?
Each lambda function is executed in a container that provides an isolated execution environment. When a function is executed for the first time, a new container with the appropriate resources will be created to execute it, and the code for the function will be loaded into the container. This happens every time the function's code is updated or when a previously created container is destroyed.
Although AWS will reuse a container when one is available, after some time this container is destroyed. There is no documentation that describe when a container is destroyed nor what event can trigger its destruction. We must keep in mind that Lambda function should be stateless and we should accept that a container could live few minutes or few seconds.
TAKEAWAY: Lambda need to create an isolated container to execute your code. This container can be destroyed at anytime. Make sure your function's code is stateless.
2- The cold start issue
The cold start issue is an important factor to keep in mind when writing a Lambda function. It refers to the fact that when a container is created, AWS needs extra time to load the code and set up the environment versus just reusing an existing container.
This is important when a lambda function need to load data, set global variables, and initiate connections to a database. Depending on your function, it can take few milliseconds to few seconds. And anything above 1 second can feel like an eternity for a user of your API!
Also note that cold start happens once for each concurrent execution of your function. Therefore, a burst of requests on your lambda can lead to multiple users experiencing a slow execution due to the cold start… not great.
When you write your Lambda function code, do not assume that AWS Lambda automatically reuses the execution context for subsequent function invocations. Other factors may dictate a need for AWS Lambda to create a new execution context, which can lead to unexpected results, such as database connection failures.
TAKEAWAY: The cold start issue can happen anytime and slow the execution of your lambda function.
3- Database connections must be closely managed

Extra care should be used when writing a Lambda function that connects to a SQL database.
Lambda is (almost) infinitely scalable. When concurrent executions of a lambda are triggered, each of these executions will set up their own global variables and database connections. Unfortunately, your database's available connections might not be enough to allow each lambda function to create their own connection. And this could result in a denial of service.
Few potential solutions:
- First, make sure your database connection is established once for each container started. One way to do that is to put the connection in a global variable. Do not forget to include some mechanism in your code to test the validity of the connection and reconnect if lost.
- Second, use a service such as Amazon RDS Proxy. RDS Proxy allows your applications to pool and share database connections to improve their ability to scale. A bit harder to set up and an extra cost associated to this service, but a more robust solution.
TAKEAWAY: Even though Lambda is highly scalable, your DB connections are not. Keep that in mind when using Lambdas.
4- Lambda works well with S3
Unless you have deep pockets and can afford a fast server to host your SQL database, a query returning large chunk of data can slow your Lambda function.
One way I used to speed up things is to use the S3 service. First I dumped an extract of my SQL table to a csv file in a S3 bucket. Next, every time my lambda function starts for the first time (cold start) the file is transferred from S3 to the /tmp/ directory of my lambda container. In python the code to do so is quite simple (to not forget to allow lambda to access S3):
import boto3 #INITIATE S3
s3_resource = boto3.resource('s3') S3_FILENAME ="file.pkl"
# A PKL file is a file created by pickle, a Python module that enables objects to be serialized to files on disk and deserialized back into the program at runtime. def download_from_s3(filename):
s3_resource.meta.client.download_file("yourS3Bucket", filename, '/tmp/' + filename) #Transfer the S3 file to the /temp folder of the lambda
download_from_s3(S3_FILENAME)
On my lambda with 1280MB of memory, a file of 125mb takes approximately 2000ms to be transferred. Still a significant amount but keep in mind it only has to be done once. The equivalent with an SQL query on my database would be more than 20 seconds. According to the doc: "data transferred between Amazon S3 […] and AWS Lambda functions in the same AWS Region is free.", so no worries regarding the cost.
TAKEWAY: You can load data directly in your Lambda's memory thanks to the S3 service. This might be a way to reduce the load on your database and increase the speed of your lambda at the same time.
5- Layers are great
Lambda function can pull in additional code and content in the form of layers. From AWS docs: "A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies. With layers, you can use libraries in your function without needing to include them in your deployment package."
Simply put, a lambda layer is a piece of code that can be reused in other lambda functions. The main advantages of layers are, in my opinion:
- It helps you keep your Lambda deployment package under 3MB, the threshold to be able to edit your code in the AWS console.
- It helps you reuse pieces of code and python packages (when using python) that are not available right out the box, such as pandas or numpy.
- Finally, it helps you write readable and clean Lambda functions with reduced operational errors that could occur during installation of dependencies.
TAKEAWAY: Use Lambda layers as much as possible to keep your deployment package small and to stay under the 3MB threshold to be able to edit your code in the AWS console.
6- Do not fear increasing the memory usage
One parameter of Lambda functions is the amount of memory available to the function. Lambda allocates CPU power linearly in proportion to the amount of memory configured. According to the docs, at 1,792 MB, a function has the equivalent of one full vCPU (one vCPU-second of credits per second).
Of course, higher memory means higher cost. For example, in the eu-west-1 region it costs $0.0000166667 for every GB of memory per second. One might think that increasing the memory of a Lambda function will result in a higher bill. But this is not entirely true for 2 reasons:
- First, higher memory lambda functions are faster, which means that you'll pay more per second, but it will take less time. Lambda charge now by milliseconds since AWS Re:Invent 2020 (a change from the 100ms minimum charge). For this reason there is always a sweet spot where you can achieve faster execution time for a lower cost. Below we achieve the lowest cost for our lambda at 1024MB memory. A 10% discount for a 9 times faster execution time.

- Second, higher memory also comes with a bigger internet connection. This means that queries and API calls are going to return data faster.
TAKEAWAY: Increased memory in lambdas do not necessarily translate in higher cost. With more memory lambdas are executed faster. Hence there is usually a sweet spot with higher memory and similar cost.
7- Lambda is cheap but heavily invoked functions might be better off running on EC2
Lambda is priced reasonably. However it is classic to end up with a larger bill than a similar code running on an EC2 instance. Here is why:
- You do not benefit from potential pseudo-parallel computation. By that I mean that lambda charge as if it was using the entire allocated vCPU even when it's not, for example when your code is waiting for a query to be executed on a database.
- There is no spot pricing. You always pay full price. Spot instances with EC2 are great and can help save quite a lot.
Below is a table summarizing the price difference of a 128MB lambda vs. a cheap T3.nano. Lambda cost is twice as much, assuming full use of the lambda, and ignoring the fact that T3.nano can run pseudo concurrent execution at no extra cost.
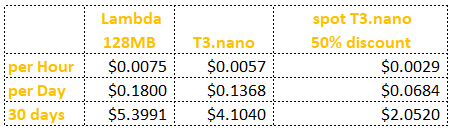
Having said that, Lambda flexibility and the fact that there is no infrastructure to manage is worth the price in my opinion. But keep in mind that heavily invoked lambda might be better off running in a EC2 instance.
TAKEAWAY: Lambda functions are not always the best option when they are heavily invoked. EC2 or Elastic Beanstalk might be good alternatives.
Conclusion
AWS Lambda is a great service. It is fast and reliable and can help deploy code without managing the infrastructure. Nonetheless it can also be expensive both in terms of time and money if not understood to a certain level. Hopefully this article helped you visualize the techniques and details I encountered while developing hundreds of AWS Lambdas.
Become a Medium member and support me on the platform!
https://medium.com/@charlesmalafosse/membership
Source: https://towardsdatascience.com/aws-lambda-7-things-i-wished-someone-told-me-63ec2021a772
0 Response to "How Easy is It to Rush Lambdas"
Post a Comment